A Python LRU Cache
Written by Katrina Ellison Geltman on Mon 05 May 2014.
Caches are structures for storing data for future use so that it doesn't have to be re-calculated each time it is accessed. You might be familiar with them in the context of the web (your browser can cache a page so that it doesn't need to be reloaded the next time you view it; a server can cache a page so that its data doesn't need to be regenerated from scratch for the next client), but caches can be used anywhere that you need to re-retrieve expensive-to- calculate data. This article ignores the web stuff to focus on the cache structure.
A cache has a finite size, so it will eventually run out of room for new results. The optimal strategy for handling subsequent requests depends on the specific situation. There are a multitude of such algorithms - Wikipedia has a nice list).
I'm going to discuss the least-recently-used (LRU) algorithm, which is probably the most intuitive strategy. It's useful when the most-recently- accessed content is likely to be the most desired in the future.
LRU Caches
In an LRU cache, when a new input arrives, the resulting output is added to the cache and the oldest output is kicked out. Adding to the cache is much like using a FIFO queue: an item is added to one end of the data structure, then eventually removed from the other. The items in the cache is always sorted by the time they were last accessed.
Retrieving items from the cache is more difficult because a regular queue doesn't allow you to access items arbitrarily. To solve this problem, we can use a hash map: retrieve an item by looking it up in the hash map, then keep track of when it was accessed by moving it to the front of the linked list.
Implementation: Linked List + Hash Map
In this implementation, results are stored in a circular, doubly-linked list, with each result node pointing to the result node just older than it. When you add a new item to the list, you remove the last item and prepend the new result to the head. If you need to access an existing item, you find it in the middle of the list and move it to the head of the list.
How do you find existing items? You use a hash table. The hashes are representations of particular inputs, and the values are the result nodes (so each result node has two pointers on it - one from the hash table, and one from the linked list).
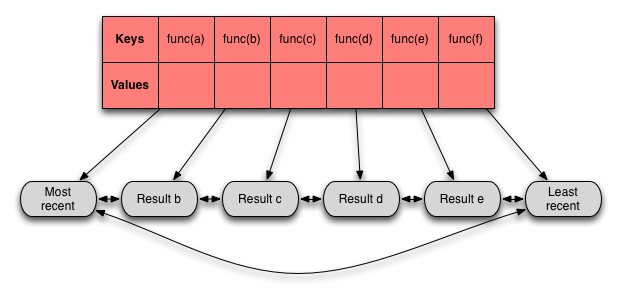
In the diagram above, hashed versions of 'func(a)', 'func(b)', etc. would serve as the keys in the hash table, and the linked list nodes containing 'Most recent', 'Result b', etc. would be the values.
I've posted a basic Python implementation on Github. It has two separate parts: the cache itself and the circular doubly linked list. The cache is an object, so you can do things like:
>>> cache = LRUCache()
>>> myfunc = lambda x,y: x*y
>>> cache.save_and_return(myfunc, 2, 3)
6
>>> cache.save_and_return(myfunc, 3, 4)
12
>>> cache.print_items()
[12, 6]
Python 3 has LRU caches built in, but they're implemented as decorators rather than objects. If you want to use a cache with a particular function, you can wrap that function with an LRU cache decorator:
from functools import lru_cache
@lru_cache(maxsize=10)
def myfunc(x, y):
return x*y
This presentation is perhaps more useful, though the underlying mechanics are exactly the same (hash map + linked list). In the current Python 3 implementation, the hash map is a basic dictionary and the 'nodes' in the linked list are 4-element lists whose items represent the previous item, the next item, the item key, and the item result.
And that's it: a simple cache implementation.